
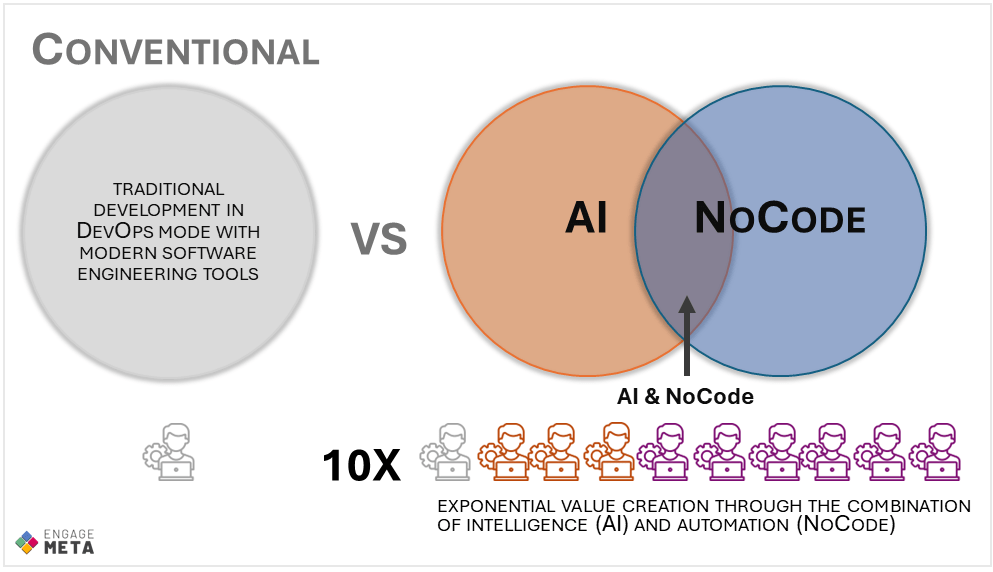
AI & NoCode
Exponential gains

The AI and NoCode case of the company Drinkizz
The Drinkizz startup has been using NoCode and AI since its launch in 2019. Pierre Bonnet, founder of the Engage-Meta community is also an investor in this company and a co-founder. The IT setup is based on a NoCode Knack database, automation with the software Make, and the use of ChatGPT, along with other NoCode tools to cover all the needs of the activity (PowerBI, Woo commerce, Chatbase, Mailchimp, Simple backup, Vietnam blockchain international…).
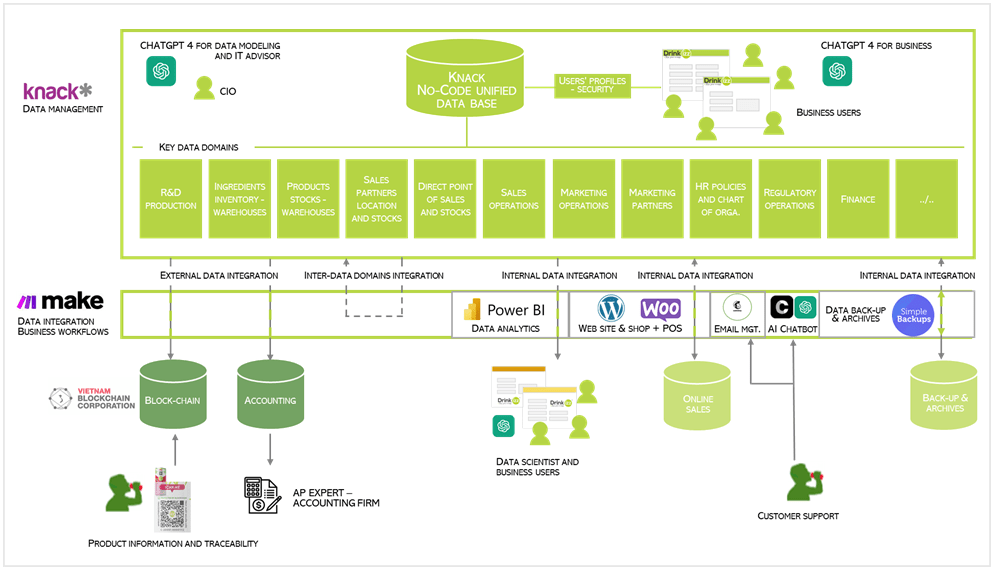
AI + NoCode = game changer
NoCode alone does not have a significant strategic impact on software production speed or profitability. However, its use with AI profoundly changes the game. AI brings intelligence, and NoCode enables its rapid automation throughout the entire information system.
Of course, this power and strong expectation of return on investment also require good governance, both in terms of modeling and project management methods. This is the focus of our work with the TRAIDA framework (Transformative AI and Data Solutions).

Learn NoCode and AI with Drinkizz's Zoom sessions
Drinkizz is a small company working on the creation and commercialization of an alternative drink to chemical sodas. Since 2019, it has relied on NoCode and AI to streamline its IT costs and generate more value for its customers and stakeholders. The significant and operational capitalization of know-how and practices in NoCode and AI is shared freely through a series of Zoom sessions called “AI by Drinkizz.” The video quality (especially in the early sessions) is not always very good, and the speakers are not professional YouTubers, but the content is rich enough to help you understand the importance of NoCode and AI in supporting innovative business operations at lower costs. Feel free to contact me (Pierre Bonnet) if you want to know more and dive into NoCode and AI practices with us. Regardless of the size of your business (solopreneur, startup, SME, large company, multinational group…), the fundamental technological approach remains the same; only the governance methods and practices need to be adapted to your specific context. We can help you clarify your NoCode and AI strategy using the TRAIDA framework from the Engage-Meta community (Transformative AI and Data Solutions).
AI by Drinkizz #11 – How Can AI Help You Identify Business Objects and Accelerate Your Business Process Creation? – Download the deck.
AI by Drinkizz #12 – Do you have the right architecture to deploy AI at scale? – Download the deck.
AI by Drinkizz #9 – Why are No-Code and AI strategic for Drinkizz’s business? – Download the deck.
AI by Drinkizz #10 – AI Assistant Prompt Versioning and Management at Drinkizz – Download the deck.
AI by Drinkizz #7 – Using AI to achieve financial independence in entrepreneurship – Download the deck.
AI by Drinkizz #8 – Accelerate your business by discovering Information from unstructured data with AI- Download the deck.
AI by Drinkizz #5 – The role of AI and NoCode in building anti-fragile businesses – Download the deck.
AI by Drinkizz #6 – How to scale your business with AI and data modeling – Download the deck.
AI by Drinkizz #3 – Knowledge management (soft skills) – Download the deck.
AI by Drinkizz #4 – Simplify database creation with AI and NoCode to accelerate business – Download the deck.
AI by Drinkizz #1 – Individual productivity – Download the deck.
AI by Drinkizz #2 – Collective productivity – Download the deck.
Example of creating an AI assistant
Here is a video that explains how I created the GPT META-Entrepreneur assistant from my book “META-Entrepreneur”.
I have published this GPT for free and open access; it can be useful for young entrepreneurs and active employees looking for inspiration on intrapreneurship. It is a nice example of digitalization and entrepreneurship approach.
It is also likely useful for beginners with GPT to understand the power of creating AI assistants.
Even with NoCode, you still need to model
The deployment of AI systems in companies and on a large scale need to use a lot of data from the company’s databases, both during their training and during prompts to enrich requests (RAG: Retrieval Augmented Generation). Since these databases and other sources such as files, archives, etc., are often heterogeneous and of varying quality, it is dangerous to connect the AIs directly to these storage areas. It is smarter to build a unified vision of all the company’s data using a powerful business model that sits in front of the heterogeneous storage areas. The AIs can then draw their data from a clean source, accompanied by security rules.
Software platforms exist for setting up this kind of system, either with a graph-oriented database approach or with the NoCode database that we regularly present in our weekly “AI by Drinkizz” Zoom sessions. But regardless of the technology used, an effort of modeling is required to achieve this unified vision of the data. It also needs to be done in a way that allows for its evolution to keep up with business changes that occur regularly. Therefore, the model must be both very clear and strict in quality management, but also well-constructed enough to accept extensions without questioning everything.
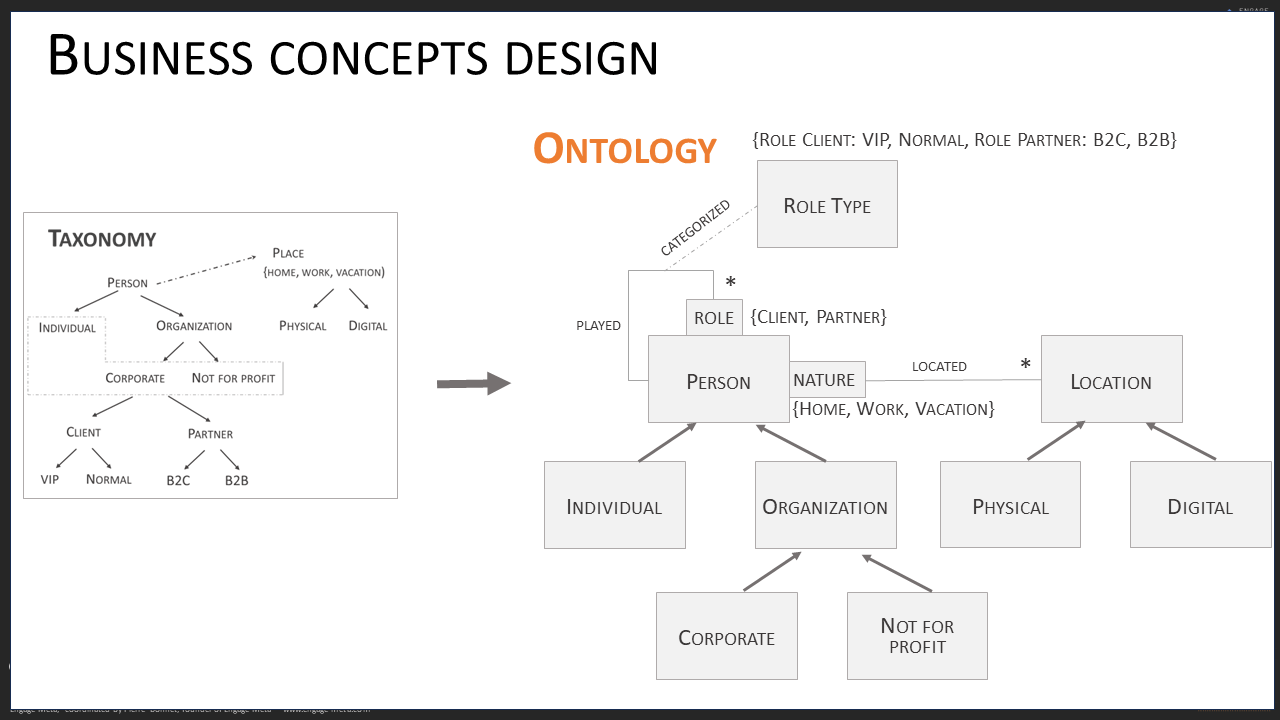
This modeling involves expertise in ontology construction, also known as the art of semantic modeling. Ontology is the art of documenting the business concepts of the company and defining their relationships as well as the rules for controlling their quality. Let’s take a closer look now.
First of all, a business concept is a key management entity for the company, such as a Client, Supplier, Invoice, Production Unit, etc. A startup has about fifteen of these, an SME more than twenty, and a large company even more. Each business concept is defined to constitute a glossary shared by the entire company. It is accompanied by a thesaurus to standardize term equivalences.
Next, the business concepts are organized into a hierarchy that describes the parent-child structures that exist between them. For example, a Client is specialized by B2B, Retail markets, etc.
Once the glossary, taxonomy, and hierarchy are in place, it is time to model the attributes of the business concepts and specify the relationships they have with each other. The semantic power of the data model greatly depends on the quality of the modeling of the relationships between business concepts. The first time you do semantic modeling, be accompanied by an expert in this discipline, at least to verify that your model is solid. You can also use an AI assistant for data modeling, but you will need to train it well before it can help you effectively (call us if you need support for this operation).
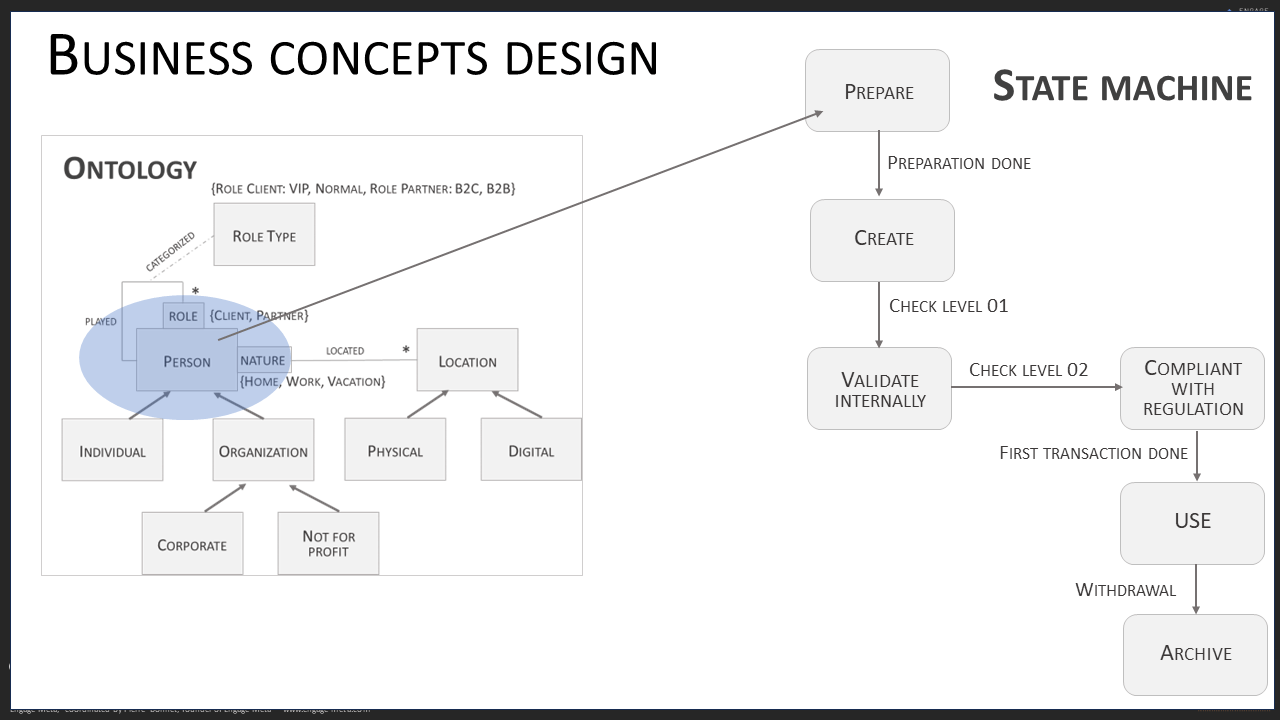
At the end of this semantic modeling, you will have built your ontologies. At this stage, it is still a static vision of unified data. A final modeling step is needed to add a more dynamic dimension. Its purpose is to control the quality of the data contained in the business concepts. These are axioms that are added to the ontology. Here, focus on universal control rules that do not depend on organizational choices. A powerful way to formalize these business axioms is to use state machines. For example, a Product business concept could have this list of possible states: R&D, Offer Catalog, Maintenance, Out of Sale… Depending on the state of a product (instance of the Product business concept), update, delete, and usage actions are possible or not.
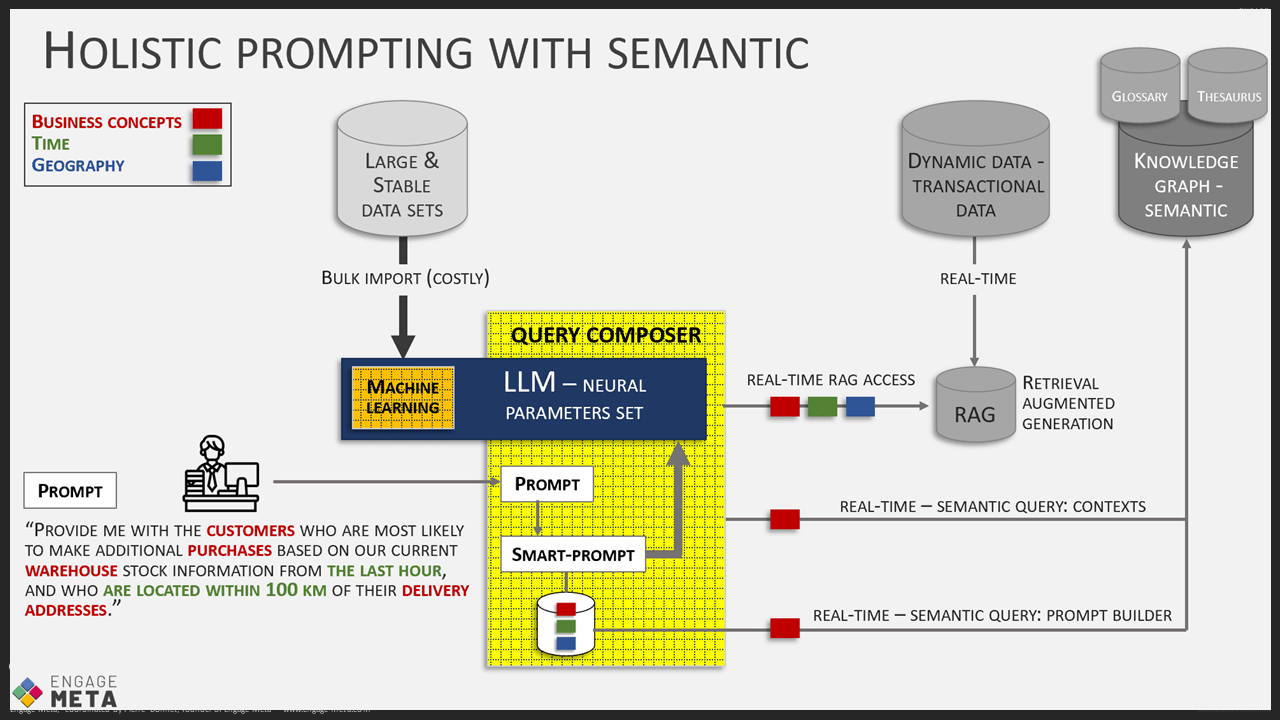
List of key advantages of having well-constructed ontologies:
- They allow the implementation of a unified data layer in front of your heterogeneous databases, or if you are starting from scratch, to have a very clean database that will follow your business evolution without creating chaos for data storage. This approach creates a digital twin of your IT on which you can plug your AIs both for their training and for prompt augmentation (RAG) by fetching real-time data in vectorized ontology instances.
- They provide the necessary classification for organizing knowledge, beyond data from databases. To better train your AIs, you will need to formalize your organization’s tacit knowledge, i.e., what your teams know but is not yet documented or well explained. All explicit knowledge is then loaded into the ontologies to complement structured data, thus increasing the knowledge base used by the AIs.
- During prompt execution, real-time access to ontologies allows on-the-fly enrichment of the request context, enabling the AIs to work better. This is the principle of RAG, which I have already mentioned several times in this post.

Conversely, during the reception of the AI-generated response, access to ontologies will allow verifying the quality of the result, for example, by checking the data sources used. This significantly reduces the negative effects of hallucinations when the AI is not used in a creative context but rather for deterministic analysis
Now you know why you need ontologies with your AI. Note that if you are starting a business, a NoCode database with ontologies is the right way to go. If you already have an existing setup, you still need ontologies, but perhaps with a technological choice oriented towards NoCode and graph-oriented databases. Depending on the scope of your existing IT, you will need to consider the best data architecture. I invite you to take a look at the TRAIDA (Transformative AI and Data solution). If you have the ambition to use AI in your company with connections to your applications and databases, I advise you to start your training in semantic modeling without delay. You will definitely need it. Call us for a training based on the real use case by Drinkizz data modeling journey<
For NoCode beginners, start here!
When you start your business or a new project, you are not able to describe all your needs at once since you don’t have the time or the knowledge to specify all the features. It is therefore difficult to define a target solution with precision and stability. If you are lucky enough to start from a blank sheet of paper, without constraints with existing systems to integrate, you can use NoCode software tools to avoid heavy IT developments as they reduce the need for IT skills. The agility of NoCode tools is a strategic asset that mature companies find difficult to exploit. They must take into account the complexity of their existing systems in order to integrate new data with digitalization. This work requires the intervention of IT specialists who no longer have the possibility to fully use the power of NoCode tools. Indeed, by confronting the complexity of existing systems, they lose some of their interest.
Example of NoCode database tools:
While more mature companies may not be able to fully utilize NoCode tools, they are still ahead of the curve in terms of data management culture. They recognize its importance to successful digitalization and already use databases. When you start a new company, you don’t always have this know-how. At first, you may feel you have a good handle on your data with a few spreadsheets, but you’ll soon find that the quality of your data plummets with its proliferation. At that point, the agility and quality of your operations will be under stress and the growth of your business will be compromised. You will then have problems along the line:
- Inventory is not accurately maintained. Spreadsheets are used to enter certain product movements and errors increase as the business grows. Frequent stops are required to conduct time-consuming manual inventories.
- Customer purchase history is stored in several heterogeneous tools. There is no consolidated view. It is difficult to determine which complementary offer to propose, which penalizes the commercial strategy.
- Refunds for returned goods are not correctly attached to invoices. The accountant lacks data to ensure the reliability of the consolidated income.
- An invoice from a supplier seems to be incorrect and you can’t find the payments already made. The accounting lettering is not managed correctly and you waste time verifying unpaid invoices.
- A promotion for an online training course is mistakenly sent to all contacts when it was reserved for active customers only. This is a loss of credibility in communication.
- A package is sent by mistake to a customer. It needs to be retrieved and returned to the correct recipient. Supply chain data quality is poor, increasing the risk of lost packages. Business growth is compromised.
Large companies can also experience these problems because of a lack of governance of their data. In this case, their digitization is put at risk. Regardless of the IT tools used, in NoCode or not, you will have to model your data so that it integrates with your digitalization. This modeling effort requires specific skills. If you are new to this field, you will find now an introduction to the management of identifiers and the concept of databases. For more advice on data modeling, do not hesitate to contact me.
Identifiers
With the Internet and mobile applications, data is all around us. In my conferences I often use this slogan: “data knows more about you than you know about it”. It allows me to highlight the importance of not losing control of data. In reality, we store more and more files, images and videos of all kinds. Thousands of emails and social network posts are passed through our hands. Keeping track of them is not easy and it is difficult to find all the digital information that accompanies our lives. Yet, this data exists permanently in heterogeneous storage spaces.
Let us take an example from real life, before extending it to the corporate world. Let’s imagine that you want to collect all the data from an anniversary. You want to go back to this event and retrieve as much information as possible. You remember using an image storage system, exchanging emails and posting on social networks. The list of gifts can be found in the order history of some online stores, but which ones? The party took place in a restaurant, but how to find the menu? All this data exists and you don’t know how to access it all at once. With every birthday, there is more data that gets lost among others. It would be nice to find them easily with a simple query, but how do you do it? Unfortunately, a query similar to that formulated in a search engine is not possible. Your data is stored in places that are not always known to the search engine. There are also private data that you do not want to publish on the Internet. Finally, you give up the hope to find everything in an accessible manner. In the future, you may want to implement a better approach to storing your important data.
If you replace this real-life example with an enterprise project, you will understand that data loss is no longer acceptable. This time, it can no longer be scattered in places that are impossible to find. If you lose information on a customer project, the quality of your business will be jeopardized. You need to get your hands on the customer’s history, their quotes, the specifications they have made for their requests, their sales exchanges, their contacts with suppliers, their current invoices, etc. In an ideal digital world, all this data would be accessible with a simple query in a search engine or through a unified application. Unfortunately, there are technical constraints that hinder this:
- You cannot store all data in spaces accessible by a search engine. There are blind spots that the engine cannot see, such as the contents of office files, databases in applications and data that is not published on the Internet. Extended indexing techniques exist, but they require IT professionals to implement them and do not address all needs. When you are setting up your digitization for the first time, it is difficult to rely on this kind of solution. The search engine can be integrated as a complement, but not as a universal solution for access to all information.
- Data have relationships to each other that the search engine does not process. For example, a package leaves from an address to a destination. There is a link between the two addresses. This kind of link is not interpretable by the engine. It will not be able to build a reliable list of all packages sent from one country to another.
- In real life (physical world), the search engine and applications are not always accessible. This is the case with a postal letter, a label on a parcel or even during a telephone exchange. It is then necessary to find another way than digital to identify the data. We will see that it is the identifier that meets this need.
- Your partners will not always have access to your applications, yet they will also need to understand your data.
To access information in a standard way regardless of heterogenous stockage spaces, the identity card on data are defined. Each important data dispose a unique identifier to describe it. It is not necessary to extend this identification to all the elementary data, but at an aggregated level. This is the group of data that form the information entity.
Information entities
Note: Information entity = Business object = Business concept
Let us take the example of a package. It is an information entity that has a unique identifier to identify each package. However, the basic data that describes it does not need an identifier: content, weight, volume, price, insured value, shipping date, etc. The customer is another information entity and also has its own identifier that aggregates its elementary data: last name, first name, address, etc. These two entities are at a good level to set up identifiers. It is not necessary to provide identifiers for the elementary data that describe them, except when they are themselves information entities. For example, an elementary data item “Customer type” in the “Customer” entity is also an information entity that must have its own identification. The objective is to standardize a list of customer types that can be reused in the entire data management system. Information entities form a layer of abstraction above the mass of elementary data. There are several types of information entities, which are listed in the following table.
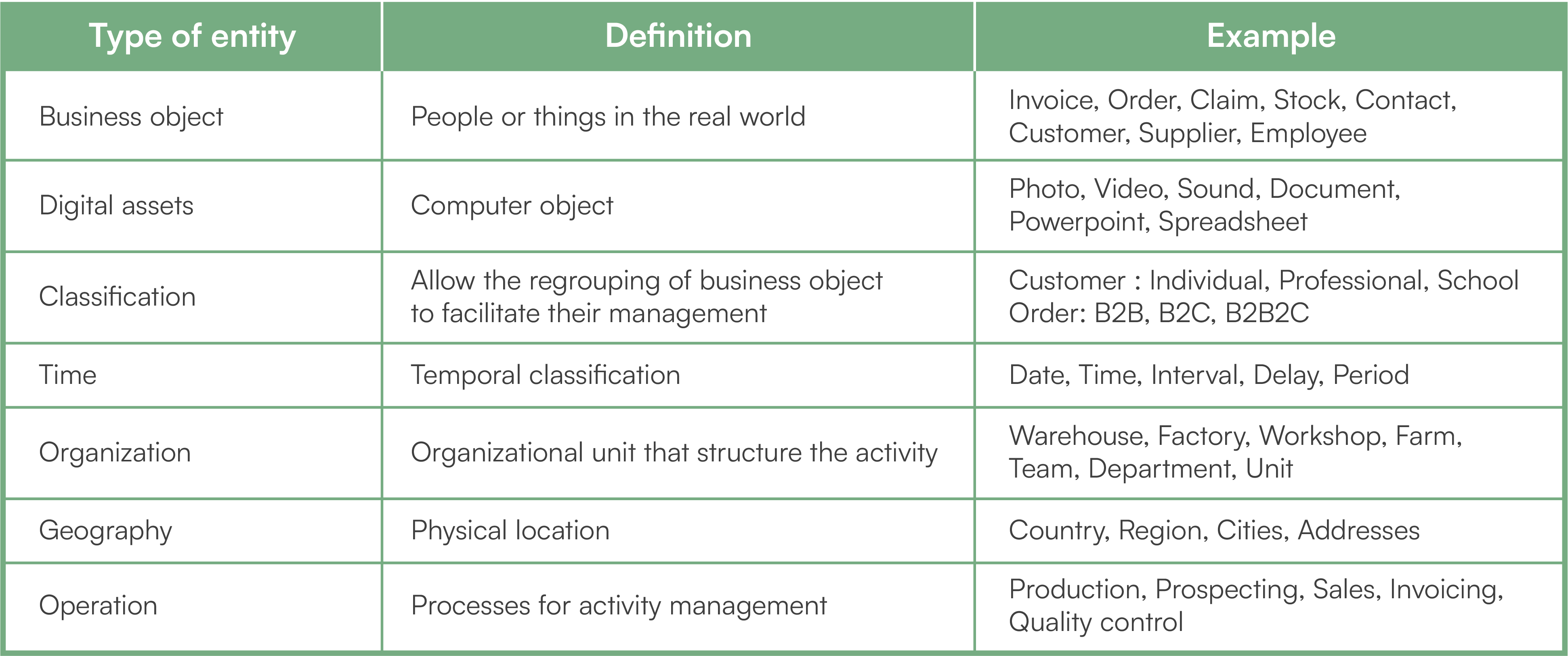
Let us use the case of a fitness product. Here we are interested in “elastic bands with varying levels of strength and built-in (climbing) clip”. The product catalog contains several configurations according to the strength levels and the number of clip. In the sales management application, it is easy to find the product using keywords such as “fitness” and “elastic band”. The complete list of such products is displayed and you just have to select the right one. Difficulties in accessing the information appear when the search is conducted outside this application.
Let us imagine an actor in the supply chain handling a package. Without its label, it is impossible to know its origin, its destination or its content. We must then decide how to represent this information in the real world. A text that describes the product will be long and ambiguous, especially if there are variants. In our example, we would write the whole description: “Three elastic bands with three different strength levels and delivered with six clips”. Since you don’t know the language used by the person concerned, you should choose a default language, probably English. Ideally, you would print the description in two languages to increase the chance of being understood, but this would clutter the label. In addition, the likelihood of the text being illegible increases with its size. There is no guarantee that the label will remain in good condition during the entire shipping process. Finally, the customer may not like the fact that everyone can see the package’s contents at first glance. So you need an identifier to locate the package, in a context where there is no application or search engine. It is an entity of information manipulated in the physical world. For example, the identifier printed on the package could be “PROD-ELAS-00002242-USA-EN-SHIP-2021-05-05” with these blocks of data:
• “PROD”: Product.
• “ELAS”: Elastic.
• “00002242”: Production number.
• “USA-EN”: Country of dispatch and destination.
• “SHIP: Shipping operation.
• “2021-05-05”: Date sent.
Another way is to identify only the package, without the product it contains. The identifier then becomes: “SHIP-B2C-004252393-USA-EN-2021-05-05”:
• “SHIP”: Shipping package.
• “B2C”: Package’s classification.
• “004252393”: Package number.
• “USA-FR”: Country of shipment and destination.
• “2021-05-05”: Date sent.
These two possible structures for the identifier depend on the company’s choice. For the person handling the packages, the identifiers cannot be interpreted without knowing the format used. Once known, they are easy to use in an email communication (copy and paste the identifier) or with a call center (oral communication the identifier). The identifier can also be completed by its equivalent in QR-Code. By flashing it, the user accesses an application that displays the concerned information entity. The quality for user experience is then improve. To generate a unique QR-Code per package, you still need to define the structure of the identifier.
There are many use cases for identifiers, for example:
- Tracking an object in real life (package).
- Regulatory requirement (invoice).
- Digital resources (file name, domain name).
- Exchange of information with third parties (list of packages to be forwarded).
- Oral communication (order code, customer support ticket number).
- Degraded solutions when access to applications is not possible.
The properties of the identifier
- Comprehensive: It is meaningful to human as it allows us to understand the information it refers to. To be legible, it should not exceed about forty alphanumeric characters, with a separator between the different composing blocks (eg a dash).
- Unique: It is not reused between multiple information entities, otherwise it would be impossible to determine what it corresponds to.
- Standard: All identifiers are based on the same basic format to render it easy to read. The codes that compose them are reused for all identifiers.
- Interoperable: Its format is compatible with existing software. The identifiers must be readable by as many software as possible in order to limit the use of transcoding tables.
- Stable: It does not change over time. If an identifier is modified, applications should be upgraded and people who have already used it should be informed. It is better to avoid this kind of impact.
The structure of the identifier
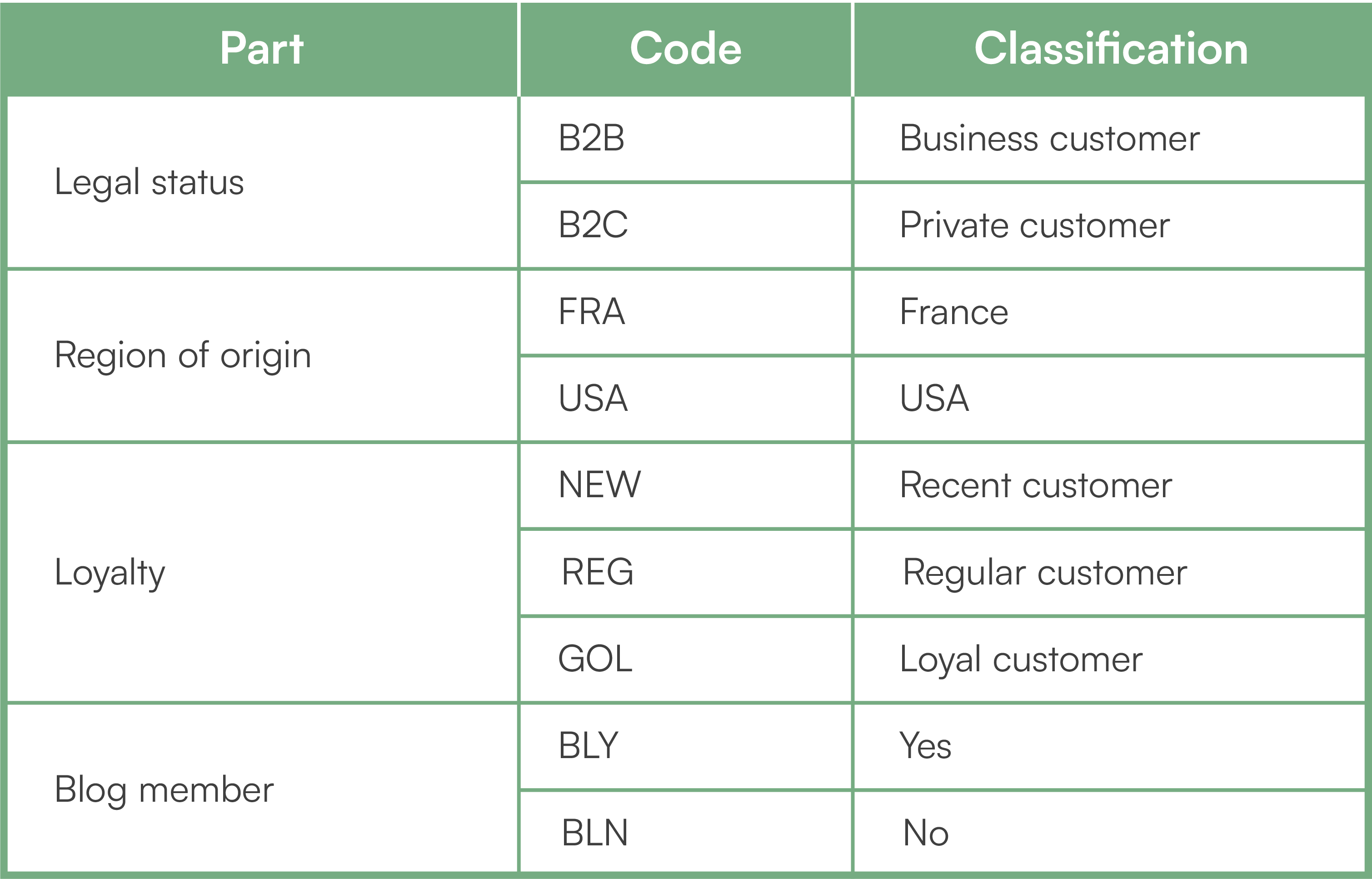
The identifier must be short enough to render it easy to read. As we have said, it should be no more than 40 characters long. Consequently, it will not be able to represent all the parts that characterize its information entity and it will only include the most significant ones. For example, if a customer is categorized by ten criteria, it is not possible to add ten codes in a row as the result would be unreadable. One or two should be retained as a significant and stable part of the customer’s profile. Let us use this customer classification system:
To build the customer’s identifier, a long code such as “B2B-FRA-NEW-BLN…” would be unreadable. In addition, it would not be sustainable since a customer can be a member of the blog and then unsubscribe or even change loyalty level. The two most stable and representative criteria are legal status and region. The identifier would then have this structure: B2B-FRA, B2C-USA, etc.
L’identifiant aurait alors cette structure : B2B-FRA, B2C-USA, etc.
Example
Let us take look at the invoice example. Its identifier is used for traceability of payments. Depending on the country, it complies with different legal constraints. Most often, it is a chronological and continuous numerical sequence. The series of invoices “001, 002, 003, 010” is not compliant. The break between the third and the tenth invoice is prohibited. Similarly, the sequence “001, 005, 002, 003, 004” is no better. This time, it is the chronology that is not respected. You can enrich the regulatory part to meet specific traceability needs, such as:
- Add a code to determine if the invoice corresponds to a B2C or B2B sale. You will then have series of invoices like this: “001-B2C, 002-B2C, 003-B2B, 004-B2C”. The “B2C” and “B2B” codes are reused for other information entities. The use of a standard separator such as the “-” makes it possible to obtain homogeneous identifier structures.
- Add customer ID and date: “001-JOHB-2102, 002-SANW-2103”. The first invoice is for customer John Bin for the month of February 2021 and the second is for customer Sandy Watts for the month of March 2021.
- Alternatively, display the identifier of the cost estimate relating to the invoice. It is then built in this way: year, invoice’s numerical sequence, customer identifier, estimate identifier, and other comment. Here is a possible identifier: “21-0653-JOHB-21-666-first payment”. This is invoice number 0653 from customer John Bin for the year 2021 relating to quote 21-666 and his first payment. The quote identifier is built in the form of the year and a numerical sequence.
Mnemonic codes (codification)
At this point in the previous example, the identifier does not include the invoice’s business purpose. It could therefore relate to an order, a complaint or even a payment. Even if it is not mandatory for an identifier to identify the purpose, it is difficult not to have this information in hand. It would be necessary to know all the formats of all the identifiers to deduce the underlying business objective and confusion would eventually arise. On the other hand, the identifier should not be made too heavy so that it is difficult to read. A compromise must therefore be found between the size of the identifier and its clarity. The use of a three-character code can be attempted. It has the advantage of condensing the identifier’s size, but it is not recommended. With a large number of types of business purpose, it is too short to distinguish them entirely.
For example, to differentiate Invoice and Investor, you already need four characters: “INVO” for Invoice and “INVE” for Investor. However, there is still a problem. Let us imagine that the object pertains to Investment. Its code is the same as that of Investor: “INVE”. This time, it would have to be extended to seven characters to distinguish them: “INVESTO” and “INVESTM”. That’s too long for an ID. We therefore prefer to limit ourselves to four characters, by adopting one of these additional rules:
- Take the first two letters, followed by two additional ones of your choice to ensure uniqueness. For example: “INVO” (Invoice) or “INVC” (Customer Invoice), “INVE” (Investor) and “INVT” (Investment).
- Alternatively, take the first two letters, followed by the last two. In our example, we then obtain: “INCE” (Invoice), “INOR” (Investor) and “INNT” (Investment).
The first rule is usually better. In the second, there might still be duplicates that another complementary rule should deal with. The invoice’s codification then becomes: “INVO-001-B2C”.
To get code ideas, you can also use abbreviation generators (1). (1) For example : www.dcode.fr/acronym-generator. With this online tool, “Invoice client” becomes “INVC” and “batch of goods” gives “BGOO”.
The construction of mnemonic codes is not self-evidential and mistake should be avoided at the beginning of the business as changes later on impact the identifiers that are already in use.
Coding of operations
For some information entities, you will need to complete the identifier with a code that indicates the operation performed. Let us take the example of a quality analysis on a batch of products that is leaving the factory. The report’s identifier shows the “Quality control” operation. We then obtain: “BGOO-00438-QCON-2021-04-02”:
- BGOO-00438: batch of goods number 00438 (business object).
- QCON-2021-04-02: Quality control carried out on April 2, 2021 (operation and date).
International standards
Some information entities are codified by international organizations such as ISO. This is the case for the list of countries with the ISO 3166(2) standard. For each country, it gives its identifier using two or three characters. You can check if your information entities can use this kind of standardization even though you do not always have to use them. It all depends on your regulatory requirements. For example, if you manage products in sensitive industries such as food or health, you will probably have to respect specific codifications(3). In addition, the use of standards gives you a common language with your stakeholders such as your customers, suppliers and partners. You will then gain in interoperability during integrations among heterogeneous systems. (2) www.iso.org/iso-3166-country-codes.html. (3) For example: www.gs1.org
Possible basic format
The following table provides a basic format that covers most business needs. You can start by referring to it, then evolve to adapt to your own context. Depending on the types of information entities, only certain parts of the format are used.
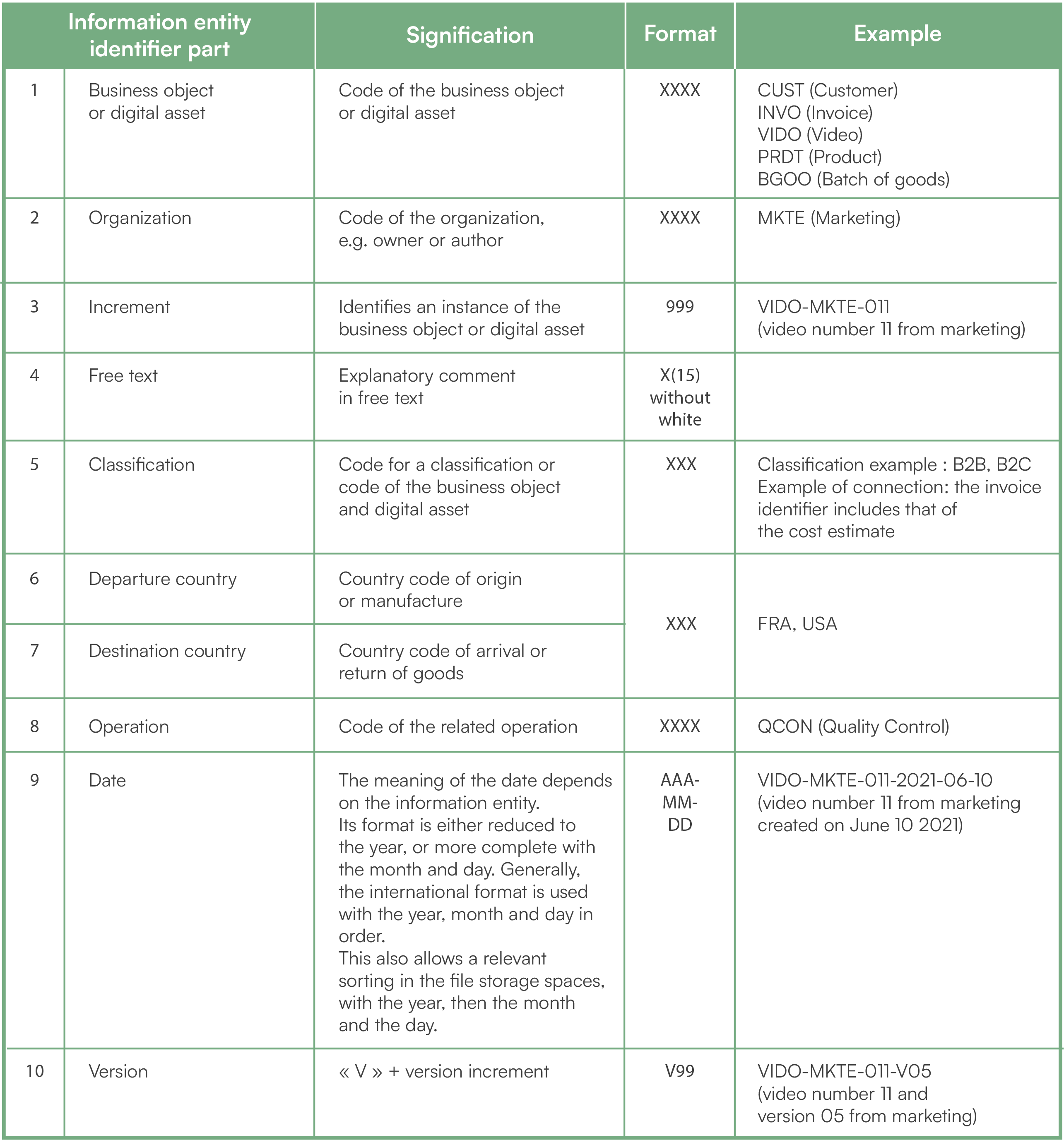
From this basic format, here are some examples of possible identifiers:
- INVO-JOHB-0653-firstPayment-21-666-2021: invoice 0653 from customer John Bin, in year 2021, for the first payment relating to quote 21-666.
- BGOO-00438- QCON-2021-04-02: quality control of batch of goods 00438 carried out on April 02, 2021.
- VIDO-MKTE-eventNewYear-2020-12-15: New Year marketing video, dated December 15, 2020.
The more standardized the identifiers are, the more rigorous the data quality is imposed. The implementation of digitalization is then more efficient.
Database
Without IT knowledge, it is difficult to be interested in databases. Yet they are omnipresent in our lives with the web and mobile applications. If you don’t know what they are used for, let us take an example with Amazon. This marketplace manages one of the largest databases in the world. With a catalog of several hundred million products, management could not be based on spreadsheets. Each product is described by dozens of elementary data such as name, price, photos or customer comments. There are therefore billions of pieces of information and the database is the only way to manage this amount coherently. It is also necessary to deal with the relationships that exist between the data. For example, each product has stocks that change in real time in different warehouses. Orders are in the billions that connect millions of customers with millions of products. This mesh between the data is considerable in size. Without a database, it is impossible to manage it. Even if you are not affected by such massive management like the case of Amazon, you still need a database for your digitalization. Beyond a thousand pieces of data, manual office-type management takes too much time and generates too many errors. Let us take an example of an online training. The following table estimates the amount of data to manage based on a few business volume assumptions.
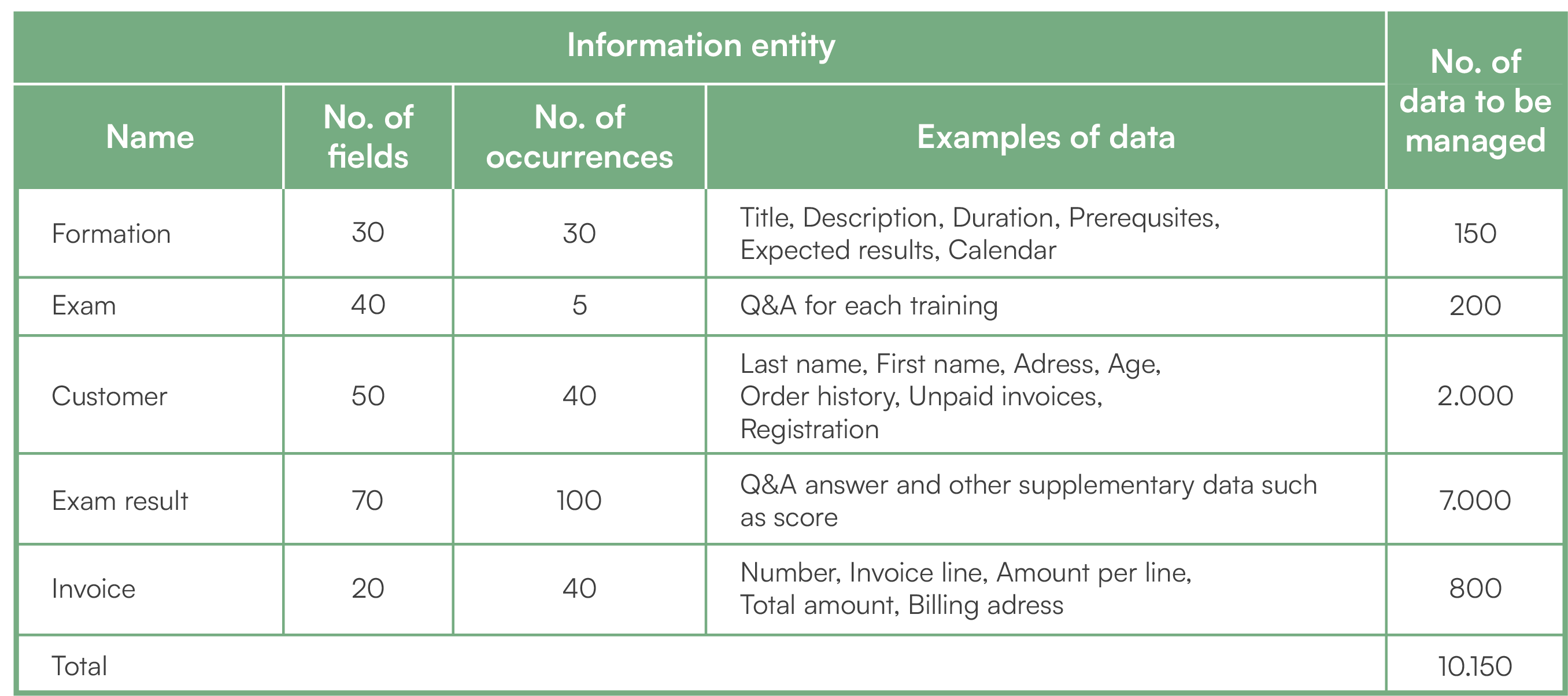
The sheer size of information already exceeds 10,000 pieces of data. Managing it in spreadsheets is prone to input error, while impossible to correctly process the links between the information entities. For example, how would you express in a spreadsheet a relationship between a customer taking a training course with exams whose results are stored in the scores. This is impossible to do in a reliable way and on a scale of several thousand data.
Let us look at a second example with the old hard-copy phone book. It listed subscribers with their phone numbers in alphabetical order over thousands of pages. Its usage was rudimentary with a manual search, by the subscriber’s name. Let us then do a thought experiment, by projecting ourselves in a science-fiction movie. The directory could be enhance with an intelligence to better exploit it in order to:
- Create links between subscribers to form groups of the same family, a club, a company or to groups of common interests. The search could be based on a group rather than a single subscriber name.
- Add data to the phone number such as age, title, profession or gender. This would require privacy rules to control access.
- Automatically exchange subscriber data with computer applications.
This science-fiction directory is a database. It makes it possible to store and exploit subscribers in a valuable way. A spreadsheet could not do this. Each row would correspond to a subscriber and each column to one of his data like his name, his phone number or his age. With this system, you cannot create links between subscribers to form groups and you do not have any privacy rules.
I still have a strong argument for the importance of a database: it allows the sharing of information by several users. This is the case of Amazon with millions of buyers and suppliers. They all use the same database(4). It is not possible do so securely with a spreadsheet. The database ensures data’s integrity, i.e. the absence of corruption of values in case of simultaneous access by several users. If you have some computer knowledge, this database implementation is based on the concept of “transaction”. In the case of Amazon, this means, for example, ensuring that the stock of a product is correctly updated, even if several orders arrive at the same time. Each customer must then be processed one after the other, since it is not possible for several customers to buy the last available product at the same time.
(4) In reality, Amazon manages several physical databases to distribute volumes and accesses, and to guarantee continuity of services with good performance, even if part of the infrastructure fails.
Setting up a first database
Your digitalization cannot do without a database. As soon as you start your activity, I recommend you to implement a database. You don’t need to master everything the first time. The NoCode tools allows you to have a technical mastery equivalent to the spreadsheet advanced user. Without these tools, you would need computer skills and you would have to launch a heavy technical project with prohibitive maintenance costs for a young company. You would not have the flexibility to make adjustments in data’s description since modifying the existing would quickly become costly. But how do you describe the data in a definitive way before you even stabilize the business? This is an impossible exercise without the NoCode. Before these tools exist, the price to pay to build a database was high. Only already mature companies or start-ups with sufficient funds could afford it. It was a difficult entry barrier for new entrepreneurs. The majority had to be content with spreadsheets and software packages dedicated to their field of activity, often too rigid for starting. Those days of cumbersome data management are over.
Today, NoCode tools allow the implementation of scalable databases without the systematic intervention of IT specialists. You then gain in agility and autonomy. It is a revolutionary movement in computing that is still nascent. Powerful data management is then within everyone’s reach. It is an important digital weapon that is not reserved only for large companies or organizations that have raised money. Obviously, the mature company can also rely on NoCode to make tactical advances with better data management and governance.
However, the NoCode tool cannot guess the data structure of your activity. It needs to be set up with their description and you will need to do this carefully. If this configuration is bad, the database will be inoperative. You will have quality problems with missing links between business objects, or others that are duplicated and generate ambiguities. You will also have a lack of genericity which will slow down the growth of your data. Despite the agility of the NoCode tool, you could have stiffen it because of a bad data description. To avoid falling into this trap, you must model your information correctly. Some basic modeling concepts are explained below:
- Table: Each information entity corresponds to a table. It is an aggregate of data around a business object such as a “Customer”, a “Product”, an “Order” or even a “Parcel”.
- Attribute (field): A table is described by a list of fields. Each field represents a piece of data. For example, the “name” of the customer is an field of the “Customer” table. To control its quality, each field respects constraints on its format. Thus, the format of a date cannot be used for the name of a customer. In the list of fields, one or more of them are used to build the identifier of the table. From a technical point of view, it is a primary key for accessing information (Primary key). It can be supplemented by a technical access key which is automatically valued by the database with an incremental counter.
- Record (Instance): An field, such as the “customer name”, takes on a value when a new customer file is created. Together with its other fields, they then form a record or an instance of the “Customer” table. So there is a different record in the table for each customer. Each record is directly accessible using its identifier, i.e. its primary key (see previous field’s definition).
- Relation: A record in a table can have links with other records in the same table or with other tables. For example, the record in the “Customer” table contains an field “List of orders” which is a relation to the “Orders” table(5). By reading the customer record, we then have all his orders. Tables have many relationships with each other. Technically, the field or group of fields that link to another table is a foreign key. This is the primary key of the information entity that is the target. (5) For the database specialist, I am referring here to a multivalued field. It is a denormalized representation that is available with the most advanced NoCode tools.
Example of relations
Let us take an example with the three tables “Customer”, “Order” and “Product”. Customer Jonh Khom ordered a fitness band and then five dumbbells in two batches. Customer Paul Durant placed a single order that includes two products: a rubber band and a dumbbell. Here are the three tables with their contents.
Customer

Product

Order
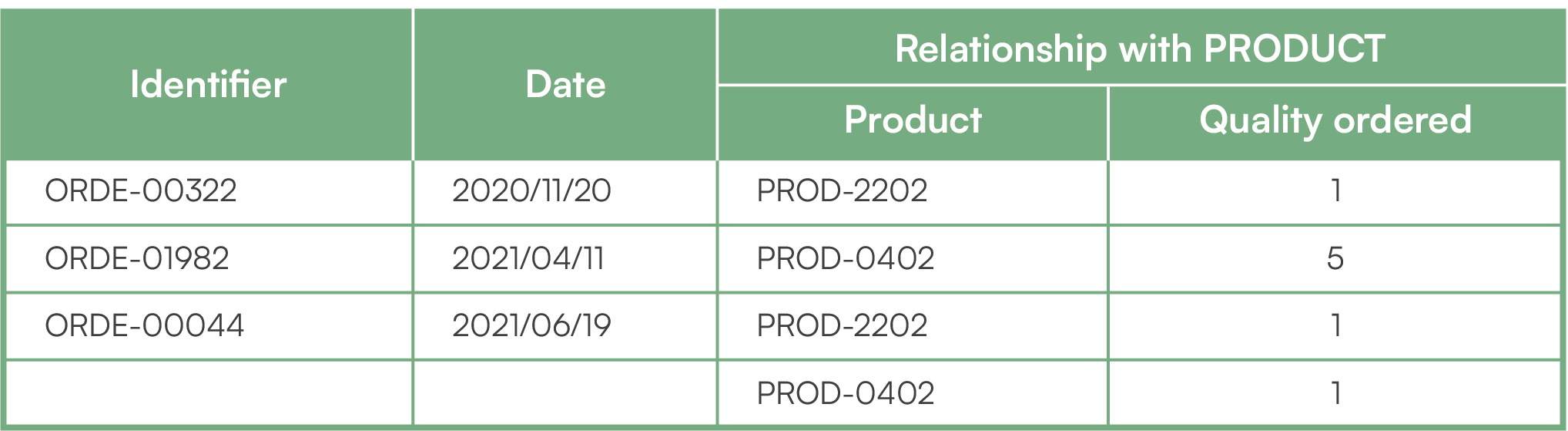
For the NoCode tool to properly manage this database, you must configure it with the correct tables, fields, and relationships. It will then be responsible for generating web forms to create, modify, store, read and delete customer, product and order records. To manage a real activity that goes beyond this theoretical example, you can imagine several tens or hundreds of tables and relations, with thousands of fields. The relevance and solidity of the modeling are therefore essential to benefit from the power of No Code, otherwise the quality of your management will deteriorate very quickly.
Advanced concept: in our example, the “Order” table does not respect the “normal forms” of the modeling because of the multivalued complex field “Relation to PRODUCT”. This type of denormalization is not always possible depending on the database used. To respect a modeling in conformity with relational algebra, it is necessary to introduce a join table which makes the link between the tables “Order” and “Product”. If you do not have an elementary knowledge of modeling to deal with this type of question, you will need to be accompanied.
The normal forms
1st: each field is atomic (not decomposable)
2nd: a non-identifying field does not depend on part of the identifier
3rd: a non-identifying field does not depend on another non-identifying field
The database has other advantages
With thousands of records in dozens of tables and relationships, it would not be possible to control this mass of information in spreadsheets of a spreadsheet. The database has other advantages:
- Data can be read in any direction. For example, you can list the customers who ordered a product or all of a customer’s orders for a particular product. Or, find the set of orders that have at least two products. All these data access requests are possible without IT development. Toutes ces requêtes d’accès aux données sont possibles sans développement informatique.
- With thousands of records, you will be able to run analysis of your activity. Imagine that you have 1,000 customers, 1,200 orders and 15 products. You will then be able to obtain the ranking of the products that sell best according to the city of your customers. With this information, you will feature in your shop the best products according to the address of each contact. You can have another classification from the date of order. Depending on the time of year, your store will then put the products with the highest probability of selling at the top of the catalog.
- Several people can use the database at the same time securely, thanks to the management of transactions and confidentiality rules. For example, your accountant will be able to consult the invoices without having the right to modify them. If you have several people on your team who access the data, access profiles will be declared according to the each responsibility.
With NoCode tools specializing in process automation(6), you can also recover data from your various digitalization software and applications in order to inject them into your database. For example, each new order from the online store is copied into a new record in the “Order” table of the database. Thanks to this automation, you can avoid re-entering the information by hand. You will have the same facility to copy the data from a contact form into the “Customer” table. Thus, all data sources are connected to your database. It then gives you a global and unified view of the information of your activity. (6) For instance: www.make.com.
Protection of personal data
For files relating to people residing in Europe, the “General Data Protection Regulation” (GDPR) requires you to obtain the agreement of each contact before saving their personal data. This regulation affects all natural persons: member, prospective customer, customer, candidate, trainee, employee, service provider, etc. You will also need to study how your Internet host applies these regulations and what their regulations are. The security and confidentiality rules may be different depending on the countries where the physical data storage centers are located. Ask them the question and read their terms of use.
Tools for creating websites, blogs or contact forms generally necessitate visitor consent page to be displayed. I recommend you to study it and configure the website with the right options according to your activity. On your website, a consent form will then be made available to your visitors.
You should document the data structure about your contacts and why you do so. In the event of an audit, this information must be presented to the auditor. For a start-up business, this is a document you can write yourself. Later on, the intervention of a lawyer will be useful to check that you take everything into account. This document will present the description of each data. For example, for the “age of customers” data:
- Name of the data: Customer’s age from the “Customer” information entity.
- Format: Numerical on two positions.
- Definition: Customer’s age on today’s date.
- Reason for storage: Used to celebrate the birthday through promotional mailing.
- Duration of storage: Two years before requesting authorization from the customer again.
You must be able to provide your contacts with a copy of their personal data, delete it, or export it in a usable format as a standard file.
The auditor will check the availability of these services.
You must publish a page on your website that details your policy on the management of personal data. For example, explain data’s retention period, the policy of their transfer to third parties, etc. You will find automatic generators of “legal notices” on the Internet. They are generated from a few questions about the purpose of your website, the company or the country of activity. Please do not forget to do so as it can result in a penalty which depends on the country where your company is located and the countries from which your contacts come from.